by Ivan Fratric, Thomas Dullien, James Forshaw and Steven Vittitoe
Intro
Many widely-deployed technologies, viewed through 20/20 hindsight, seem like an odd or unnecessarily risky idea. Engineering decisions in IT are often made with imperfect information and under time pressure, and some oddities of the IT stack can best be explained with “it seemed like a good idea at the time”. In the personal view of some of the authors of this post, WPAD (“Web Proxy Auto Discovery Protocol” - and more specifically “Proxy Auto-Config”), is one of these oddities.
At some point in the very early days of the Internet - prior to 1996 - engineers at Netscape decided that JavaScript was a good language to write configuration files in. The result was PAC - a configuration file format that works as follows: The browser connects to a pre-configured server, downloads the PAC file, and executes a particular Javascript function to determine proper proxy configuration. Why not? It certainly is more expressive and less verbose than (let’s say) XML, and seems a reasonable way to provide configurations to many clients.
PAC itself was coupled with a protocol called WPAD - a protocol that makes it unnecessary for the browser to have a pre-configured server to connect to. Instead, WPAD allows the computer to query the local network to determine the server from which to load the PAC file.
Somehow this technology ended up being an IETF draft which expired in 1999, and now, in 2017, every Windows machine will ask the local network: “Hey, where can I find a Javascript file to execute?”. This can happen via a number of mechanisms: DNS, WINS, but - perhaps most interestingly - DHCP.
In recent years, browser exploits have mutated from being primarily DOM-oriented to targeting Javascript engines directly, so the mere mention that we can get Javascript execution over the network without the browser was motivating. An initial investigation revealed that the JS Engine responsible for executing these configuration files was jscript.dll - the legacy JS Engine that also powered IE7 and IE8 (and is still reachable in IE11 in IE7/8 compatibility mode if appropriate script attributes are used). This is both good and bad - on the one hand, it means that not every Chakra bug is automatically a local network remote attack, but on the other hand, it means that some pretty old code will be responsible for executing our Javascript.
Security researchers have previously warned about the dangers of WPAD. But, as far as we know, this is the first time that an attack against WPAD is demonstrated that results in the complete compromise of the WPAD user’s machine.
Windows is certainly not the only piece of software that implements WPAD. Other operating systems and applications do as well. For example Google Chrome also has a WPAD implementation, but in Chrome’s case, evaluating the JavaScript code from the PAC file happens inside a sandbox. And other operating systems that support WPAD don’t enable it by default. This is why Windows is currently the most interesting target for this sort of attack.
Web Proxy Auto-Discovery
As mentioned above, WPAD will query DHCP and DNS (in that order) to obtain a URL to connect to - apparently LLMNR and Netbios can also be used if no response from DNS is available. Some peculiarities of WPAD-over-DNS enable surprising attack vectors.
Attack scenario: Local network via DHCP
In the most common scenario, a machine will query the local DHCP server using option code 252. The DHCP server replies with a string - like “http://server.domain/proxyconfig.pac”, which specifies a URL from which the configuration file should be fetched. The client then proceeds to fetch this file, and execute the contents as Javascript.
In a local network, an attacker can simply impersonate the DHCP server - either by ARP games or by racing the legitimate DHCP. The attacker can then provide a URL where the malicious Javascript file is hosted.
Attack scenario: Remote over the internet via privileged position and DNS
Aside from the local-network attack scenario, the fact that lookup for WPAD may also happen via DNS creates a secondary attack scenario. Many users configure their computers to perform DNS lookups against one of the public, globally visible DNS servers (such as 8.8.8.8, 8.8.4.4, 208.67.222.222 and 208.67.220.220). In such a scenario, a machine will send DNS queries (such as wpad.local) to the server which sits outside of the local network. An attacker in a privileged position on the network (e.g. a gateway, or any other upstream host) can monitor the DNS queries and spoof a reply, directing the client to download and execute a malicious Javascript file.
Setups like these seem to be common - according to this Wikipedia entry, a nontrivial proportion of the traffic that the DNS root servers see are .local requests.
Attack scenario: Remote over the internet via malicious wpad.tld
A particular oddity of WPAD is that it recursively walks the local machine name to find domains to query. If a machine is called “laptop01.us.division.company.com”, the following domains are supposedly queried in order:
- wpad.us.division.company.com
- wpad.division.company.com
- wpad.company.com
- wpad.com
This has (according to this Wikipedia entry) in the past led to people registering wpad.co.uk and redirecting traffic to an online auction site. Further quoting from that entry:
Through the WPAD file, the attacker can point users' browsers to their own proxies and intercept and modify all of WWW traffic. Although a simplistic fix for Windows WPAD handling was applied in 2005, it only fixed the problem for the .com domain. A presentation at Kiwicon showed that the rest of the world was still critically vulnerable to this security hole, with a sample domain registered in New Zealand for testing purposes receiving proxy requests from all over the country at the rate of several a second. Several of the wpad.tld domain names (including COM, NET, ORG, and US) now point to the client loopback address to help protect against this vulnerability, though some names are still registered (wpad.co.uk).
Thus, an administrator should make sure that a user can trust all the DHCP servers in an organisation and that all possible wpad domains for the organisation are under control. Furthermore, if there's no wpad domain configured for an organisation, a user will go to whatever external location has the next wpad site in the domain hierarchy and use that for its configuration. This allows whoever registers the wpad subdomain in a particular country to perform a man-in-the-middle attack on large portions of that country's internet traffic by setting themselves as a proxy for all traffic or sites of interest.
The IETF draft, on the other hand, explicitly asks for clients to only allow “canonical” (e.g. non-top-level domains). We have not investigated to what extent clients implement this, or if second-level domains (such as .co.uk) are the culprit in the historical cases of traffic redirection.
Either way: Bugs in the Javascript engine under consideration can be exploited remotely via the internet if one manages to register wpad.$TLD for a given organization’s TLD, provided said TLD is not explicitly blacklisted by the client implementation. Given that the IETF draft from 1999 refers to a list of TLDs from 1994 (RFC1591), it is unlikely that clients have been updated to reflect the proliferation of new TLDs.
Our attempts to register wpad.co.$TLD for a variety of TLDs were not (yet) successful.
Bugs
We spent some time looking for bugs in jscript.dll and employed both manual analysis and fuzzing. JScript initially posed some challenge because a lot of “features” useful for triggering bugs in JavaScript engines can’t be used in JScript, simply due to it being too old to support them. For example:
- There are no multiple arrays types (int array, float array etc.). Thus confusing one array type for another is not possible.
- There are not as many optimizations (“fast paths”) as in the newer, faster JavaScript engines. These fast paths are often the source of bugs.
- It is not possible to define a getter/setter on a generic JavaScript object. It is possible to call defineProperty but only on DOM objects which doesn’t work for us as there won’t be a DOM in the WPAD process. Even if there were, a lot of JScript functions will simply fail when called on a DOM object with a message “JScript object expected”.
- It is impossible to change an object’s prototype once it is created (i.e. there is no “__proto__” property).
However, JScript does suffer from more “old-school” vulnerability classes such as use-after-free. JScript’s garbage collector is described in this old MSDN article. JScript uses a non-generational mark-and-sweep garbage collector. Essentially, whenever a garbage collection is triggered, it marks all the JScript objects. Then it scans them starting from a set of “root” objects (sometimes also referred to as “scavengers”) and clears the mark from all the objects it encounters. All the objects that are still marked get deleted. One recurring problem is that local variables on the stack aren’t added to the list of root objects by default, meaning that a programmer needs to remember to add them to the garbage collector’s root list, especially if those variables refer to objects that can be deleted during the function’s lifetime.
Other possible types of vulnerabilities include buffer overflows, uninitialized variables etc.
For fuzzing, we used the grammar-based Domato fuzzing engine and wrote a new grammar specifically for JScript. We identified interesting built-in properties and functions to add to the grammar by looking at EnsureBuiltin methods of various JScript objects. The JScript grammar has been added to the Domato repository here.
Between fuzzing and manual analysis we identified seven security vulnerabilities. They are summarized in the table below:
Vulnerability class | Vulnerabilities affecting IE8 mode | Vulnerabilities affecting IE7 mode |
Use-after-free | ||
Heap overflow | ||
Uninitialized variable | ||
Out-of-bounds read | ||
Total | 7 | 5 |
At the time of publishing this blog post, all the bugs have been fixed by Microsoft.
The table breaks down the vulnerabilities by class and compatibility mode required to trigger them. JScript in WPAD is equivalent to running a script in IE7 compatibility mode, which means that, although we found 7 vulnerabilities, “only” 5 of them can be triggered in WPAD. However, the other vulnerabilities can still be used against Internet Explorer (including IE11) when put into IE8 compatibility mode by a malicious webpage.
Exploit
Understanding JScript VARs and Strings
Since in the remainder of this blogpost we’re going to talk about JScript VARs and Strings a lot, it is useful to describe these before going deeper into how the exploits work.
JScript VAR is a 24-byte (on 64-bit builds) structure that represents a JavaScript variable and is essentially the same as the VARIANT data structure described in this MSDN article. In most cases (sufficient to follow the exploit) its memory layout looks like this:
Offset | Size | Description |
0 | 2 | Variable type, 3 for integer, 5 for double, 8 for string etc. |
8 | 8 | Depending on the type, either an immediate value or a pointer |
16 | 8 | Unused for most types |
For example, we can represent a double precision number by a VAR that has 5 written in the first 2 bytes (indicating the double type), followed by an actual double value at offset 8. The last 8 bytes are going to be unused but they are going to be copied around if a value of another VAR is copied from this VAR.
A JScript string is a type of VAR that has the type 8 and a pointer at offset 8. The pointer points into a BSTR structure described here. On 64-bit builds BSTR layout looks like this:
Offset | Size | Description |
0 | 4 | Unused |
4 | 4 | String length in bytes not counting the null character at the end |
8 | length+2 | String characters (16-bit) followed by a null character |
A String VAR points directly to the character array, which means that, to obtain a String's length, the pointer needs to be decremented by 4 and the length read from there. Note that BSTRs are handled by OleAut32.dll and are allocated on a separate heap (i.e. a different heap than is being used for other JScript objects).
Freeing of BSTRs is also different than for most objects because, instead of directly freeing a BSTR, when SysFreeString is called, it first puts a string in a cache controlled by OleAut32.dll. This mechanism is described in detail in Heap Feng Shui in JavaScript.
Stage 1: Infoleak
The purpose of the infoleak will be to obtain the address of a string in memory whose content we fully control. We won’t be leaking any executable module addresses at this point, that will come later. Instead, the goal is to defeat high-entropy heap randomization and make the second stage of the exploit reliable without having to use heap spraying.
For the infoleak we’re going to use this bug in RegExp.lastParen. To understand the bug let’s first take a closer look at the memory layout of jscript!RegExpFncObj which corresponds to the JScript RegExp object. At offset 0xAC RegExpFncObj contains a buffer of 20 integers. Actually these are 10 pairs of integers: the first element of the pair is the start index into the input string and the second element is the end index. Whenever RegExp.test, RegExp.exec or String.search with a RegExp parameter encounter a capturing group (parentheses in the RegExp syntax), the start and end index of the match are stored here. Obviously in the buffer there is space for only 10 matches, so only the first 10 matches are stored in this buffer.
However, if RegExp.lastParen is called and there were more than 10 capturing groups, RegExpFncObj::LastParen will happily use the number of capturing groups as an index into the buffer, leading to out-of-bounds read. Here is a PoC:
var r= new RegExp(Array(100).join('()'));
''.search(r);
alert(RegExp.lastParen);
The 2 indices (let’s call them start_index and end_index) are read outside the bounds of the buffer and can thus be made arbitrarily large. Assuming this first out-of-bounds access doesn’t cause a crash, if the values in those indices are larger than the length of the input string, then a second out-of-bounds access is going to occur which allows us to read a outside the bounds of the input string. The string content read out-of-bounds like this is going to be returned to the caller in a String variable where it can be examined.
This second out-of-bounds read is what we’re going to use, but first we need to figure out how to get controlled data into start_index and end_index. Fortunately, looking at the layout of RegExpFncObj, there is data we control after the end of the index buffer: RegExp.input value. By setting RegExp.input to an integer value and using a RegExp composed of 41 sets of empty parentheses, when RegExp.lastParen gets called, start_index is going to be 0 and the end_index is going to be whatever value we wrote to RegExp.input.
If we make an input string adjacent to a freed string, then by reading after the bounds of input string, we can obtain the heap metadata such as the pointers to the other free heap segments (Left, Right and Parent node in the red-black tree of heap chunks, see Windows 10 Segment Heap Internals for more information). Image 1 shows the relevant objects at the moment of infoleak.
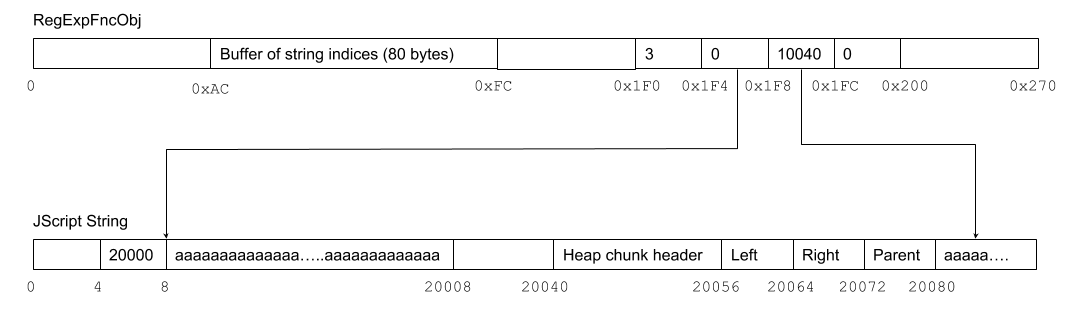
Image 1: Heap infoleak layout
We are using 20000 bytes-long strings as input in order for them not to be allocated on the Low Fragmentation Heap (LFH can only be used for allocations of 16K bytes and smaller) since the heap metadata for the LFH is different and does not include useful pointers in Windows 10 Segment Heap. Additionally, LFH introduces randomness that would affect our ability to place the input string next to a freed string.
By reading the heap metadata out of the returned string, we can obtain an address of a freed string. Then, if we allocate a string of the same size as the freed string, it might be placed at this address and we achieved our goal, that is we know the address of memory of a string whose content we control.
The whole infoleak process looks like this:
- Allocate 1000 10000-character strings (note: 10000 characters == 20000 bytes).
- Free every second one.
- Trigger the info leak bug. Use one of the remaining strings as an input strings and read 20080 bytes.
- Analyze the leaked string and obtain the pointer to one of the freed strings.
- Allocate 500 strings of the same length as the freed strings (10000 characters) with a specially crafted content.
The content of the specially crafted strings is not important at this stage, but will be important in the next one, so it will be described there. Also note that, by examining heap metadata, we can easily determine which heap implementation the process is using (Segment Heap vs NT heap).
Images 2 and 3 show heap visualization created using Heap History Viewer at the time around the infoleak. Green stripes represent allocated blocks (occupied by strings), grey stripes represent allocated blocks that are then freed by later allocated again (the stings we free and then reallocate after triggering the infoleak bug) and the white stripes represent data that is never allocated (guard pages). You can see how strings get allocated as the time passes, then half of them are freed (grey ones) and sometime later get allocated again (the stripes become green).
We can see that there are going to be guard pages after every 3 allocations of this size. Our exploit is never actually going to touch any of these guard pages (it reads too little data past the end of the string for that to occur) but in ⅓ of the cases there won’t be a free string after the input string for the infoleak so the expected heap metadata will be missing. We can, however, easily detect this case and either trigger the infoleak bug using another input string or silently abort the exploit (note: we didn’t trigger any memory corruption up to this point).

Image 2: Heap Diagram: Showing the evolution of the heap over time

Image 3: Step-by-step illustration of leaking a pointer to a string.
Stage 2: Overflow
In stage 2 of the exploit we’re going to use this heap overflow bug in Array.sort. In case the number of elements in the input array to Array.sort is larger than Array.length / 2, JsArrayStringHeapSort (called by Array.sort if a comparison function isn’t specified) is going to allocate a temporary buffer of the same size as the number of elements currently in the array (note: can be smaller than array.lenght). It is then going to attempt to retrieve the corresponding elements for every array index from 0 to Array.length and, if that element exists, add it to the buffer and convert to string. If the array doesn’t change during the lifetime of JsArrayStringHeapSort, this will work fine. However, JsArrayStringHeapSort converts array elements into strings which can trigger toString() callbacks. If during one of those toString() callbacks elements are added to the array where they were previously undefined, an overflow is going to occur.
To understand the bug and its exploitability better let’s take a closer look at the structure of the buffer we’ll overflow out of. It is already mentioned that the array will have the same size as the number of elements currently in input array (to be exact, it is going to be number of elements + 1). Each element of the array is going to be 48 bytes in size (in a 64-bit build) with the following structure:
Offset | Size | Descripion |
0 | 8 | Pointer to a string VAR after the original VAR at offset 16 is converted to string |
8 | 4 | Index (int) of the current element |
16 | 24 | VAR holding the original array element |
40 | 4 | int 0 or 1 depending on the type of VAR at offset 16 |
During JsArrayStringHeapSort, each element of the array with index < array.length is retrieved, and if the element is defined the following happens:
- The array element is read into VAR at offset 16
- The original VAR is converted into a string VAR. A pointer to the string VAR is written at offset 0.
- At offset 8, the index of the current element in array is written
- Depending on the original VAR type, 0 or 1 is written at offset 40
Looking at the structure of the temporary buffer, we don’t control a lot of it directly. If an array member is a string, then at offsets 0 and 24 we’re going to have a pointer that, when dereferenced, at offset 8 contains another pointer to the data we control. This is, however, one level of indirection larger than what would be useful to us in most situations.
However, if a member of array is a double precision number, then at offset 24 (corresponding to offset 8 into the original VAR) the value of that number is going to be written and it is directly under our control. If we create a number with the same double representation as the pointer obtained in Stage 1, then we can use our overflow to overwrite a pointer somewhere after the end of the buffer with a pointer to the memory we directly control.
Now the question becomes, what can we overwrite in this way to advance the exploit. One of the possible answers presents itself if we take a closer look at how Objects work in JScript.
Each Object (more specifically, a NameList JScript object) is going to have a pointer to a hashtable. This hashtable is just an array of pointers. When a member element of an Object is accessed, a hash of the name of the element is computed. Then, a pointer at the offset corresponding to the lowest bits of the hash is dereferenced. This pointer points to a linked list of object elements and this linked list is traversed until we reached an element with the same name as the requested element. This is shown in image 4.

Note that, when the name of the element is less than 4 bytes, it is stored in the same structure as the VAR (element value). Otherwise, there is going to be a pointer to the element name. Name lengths <=4 are sufficient for us so we don’t need to go into the details of this.
An Object hashtable is a good candidate to overwrite because:
- We can control which elements of it are dereferenced by accessing the corresponding object members. Elements we overwrite with data we don’t control will simply never be accessed.
- We have limited control over the hashtable size by controlling how many members the corresponding object has. For example a hashtable starts with 1024 bytes, but if we add more than 512 elements to the object, the hashtable will be reallocated to 8192 bytes.
- By overwriting a hashtable pointer with a pointer to data we control, we can create fake JScript vars in the data we control and access them simply by accessing the corresponding object members.
To perform the overwrite reliably we do the following:
- Allocate and free a lot of memory blocks with size 8192. This will turn on the Low Fragmentation Heap for allocation of size 8192. This will ensure that the buffer we are overflowing out of, as well as hashtable we are overflowing into will be allocated on the LFH. This is important because it means there will be no other allocations of other sizes nearby to spoil the exploit attempt (since an LFH bucket can only contain allocations of a certain size). This in turn ensures that we will be overwriting exactly what we want with high reliability.
- Create 2000 objects, each containing 512 members. In this state, each object has a hashtable of 1024 bytes. However, adding just one more element to one of these objects will cause its hashtable to grow to 8192 bytes.
- Add the 513 element to the first 1000 objects, causing 1000 allocations of 8192-byte hashtables.
- Trigger Array.sort with an array with length=300 and 170 elements. This allocates a buffer of size (170+1)*48=8208 bytes. Due to LFH granularity this object will be allocated in the same LFH bucket as 8192-byte hashtables.
- Immediately (in the toString() method of the first array element) add 513th element to the second 1000 objects. This makes us pretty certain that by now the sort buffer is neighboring one of the hashtables. In the same toString() method also add more elements to the array which will cause it to grow out-of-bounds.
Image 5 shows heap visualization around the address of the sort buffer (red line). You can see the sort buffer is surrounded by allocations of similar size which all correspond to Object hashtables. You can also observe the LFH randomness in the sense that subsequent allocations are not necessarily on subsequent addresses, however this makes no difference for our exploit.

Image 5: Heap visualization around the overflow buffer
As mentioned previously, we crafted our overflow in such a way that some of the hashtable pointers of an unlucky JScript object will get overwritten with pointers into the data we control. Now finally what exactly we put into this data comes into play: we crafted it in such a way that it contains 5 (fake) JavaScript variables:
- Variable 1 just contains number 1337.
- Variable 2 is of special type 0x400C. This type basically tells JavaScript that the actual VAR is pointed to by pointer at offset 8, and this pointer should be dereferenced before reading or writing this variable. In our case, this pointer points 16 bytes before Variable 1. This basically means that the last 8-byte qword of Variable 2 and the first 8-byte qword of Variable 1 overlap.
- Variable 3, Variable 4 and Variable 5 are simple integers. What is special about them is that they contain numbers 5, 8 and 0x400C in their last 8 bytes, respectively.
The state of the corrupted Object after the overflow is shown in image 6.
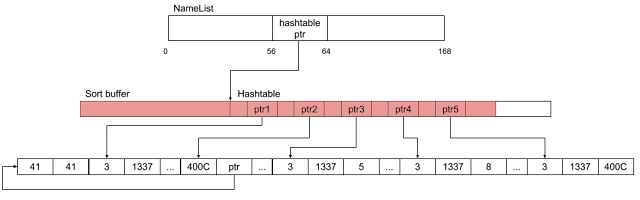

Image 6: State of objects after the overflow. Red areas indicate where the overflow occurred. Each box in the bottom row (except those marked as ‘...’) corresponds to 8 bytes. Data contained in ‘...’ boxes is omitted for clarity
We can access Variable 1 by simply accessing the corrupted object at the correct index (let’s call it index1) and similarly for Variables 2-5. In fact, we can detect which Object we corrupted by accessing index1 of all objects and seeing which now has the value 1337.
Overlapping Variable 1 and Variable 2 has the effect that we can change the type (first WORD) of Variable 1 into 5 (double), 8 (string) or 0x400C (pointer). We do this by reading Variable 2, 3 or 4 and then writing the read value into Variable 2. For example the statement
corruptedobject[index2] = corruptedobject[index4];
Has the effect that the type of Variable 1 will be changed into a String (8), while all other fields of Variable 1 will remain unchanged.
This layout gives us several very powerful exploitation primitives:
- If we write some variable that contains a pointer into Variable 1, we can disclose the value of this pointer by changing the type of Variable 1 to double (5) and reading it out
- We can disclose (read) memory at an arbitrary address by faking a String at that address. We can accomplish this by first writing a double value corresponding to the address we want to read into Variable 1 and then changing the type of Variable 1 toString (8).
- We can write to an arbitrary address by first writing a numeric value corresponding to the address into Variable 1, then changing the type of Variable 1 to 0x400C (pointer) and finally writing some data to Variable 1.
With these exploit primitives, normally getting the code execution would be pretty simple, but since we’re exploiting Windows 10 we first need to bypass the Control Flow Guard (CFG).
Stage 3: CFG bypass
There are probably other known bypasses we could have used here, but it turns out that there are some very convenient bypasses (once attacker has a read/write primitive) specific to jscript.dll. We are going to exploit the facts that:
- Return addresses are not protected by CFG
- Some Jscript objects have pointers to the native stack
Specifically, each NameTbl object (in Jscript, all JavaScript objects inherit from NameTbl), at offset 24 holds a pointer to CSession object. CSession object, at offset 80 holds a pointer to near the top of the native stack.
Thus, with an arbitrary read, by following a chain of pointers from any JScript object, it is possible to retrieve a pointer to the native stack. Then, with an arbitrary write, it is possible to overwrite a return address, bypassing CFG.
Stage 4: Getting code execution as Local Service
With all the exploit elements in place, we can now proceed to getting the code execution. We are doing it in these steps:
- Read the address of jscript.dll from a vtable of any JScript object
- Read the address of kernel32.dll by reading the import table of jscript.dll
- Read the address of kernelbase.dll by reading the import table of kernel32.dll
- Scan kernel32.dll for rop gadgets we are going to need
- Get the address of WinExec from the export table of kernel32.dll
- Leak the stack address as explained in the previous section
- Prepare the ROP chain and write it to the stack, starting with a return address closest to our leaked stack address.
The ROP chain we are using looks like this:
[address of RET] //needed to align the stack to 16 bytes
[address of POP RCX; RET] //loads the first parameter into rcx
[address of command to execute]
[address of POP RDX; RET] //loads the second parameter into rdx
1
[address of WinExec]
By executing this ROP chain we are calling WinExec with a command we specified. For example, if we run the command ‘cmd’ we are going to see a command prompt being spawned, running as Local Service (the same user WPAD service runs as).
Unfortunately, from a child process running as Local Service, we can’t talk to the network, but what we can do is drop our privilege escalation payload from memory to a disk location Local Service can write and execute it from there.
Stage 5: Privilege escalation
While the Local Service account is a service account, it doesn’t have administrative privileges. This means the exploit is quite limited in what it can access and modify on the system, especially to persist after exploitation or after the system has been rebooted. While there’s always likely to be an unfixed privilege escalation in Windows we don’t need to find a new vulnerability to escalate our privileges. Instead we can abuse a built-in feature to escalate from Local Service to the SYSTEM account. Let’s look at the privileges that the service account for WPAD has been granted:

Image 7: Service Access Token’s Privileges showing Impersonate Privilege
We’ve only got three privileges, but the highlighted privilege, SeImpersonatePrivilege is important. This privilege allows the service to impersonate other users on the local system. The reason the service has impersonate privilege is it accepts requests from all users on the local system and might need to perform actions on their behalf. However, as long as we can get an access token for the account we want to impersonate we can get the full access rights of the token’s user account, including SYSTEM which would give us administrator rights on the local system.
Abusing impersonation is a known issue with the Windows security model (you can find more details by searching for Token Kidnapping). Microsoft have tried to make it harder to get an access token for a privileged user but it’s virtually impossible to close all possible routes. For example, James discovered a vulnerability in Windows’ implementation of DCOM which allows any user to get access to a SYSTEM access token. While Microsoft fixed the direct privilege escalation vulnerability they didn’t, or perhaps couldn’t, fix the token kidnapping issue. We can abuse this feature to capture the SYSTEM token, impersonate the token, then completely compromise the system, such as installing a privileged service.
There’s an existing implementation of the token kidnapping via DCOM (RottenPotato) however the implementation was designed for use with the Metasploit framework’s getsystem command which we’re not using. Therefore, we implemented our own simpler version in C++ which directly spawns an arbitrary process with a SYSTEM token using the CreateProcessWithToken API. As a bonus we were able to compile it to an executable of 11KiB in size, much smaller than RottenPotato, which made it easier to drop to disk and run from the ROP payload.
Tying it all together
When the WPAD service queries for the PAC file, we serve the exploit file which exploits the WPAD service and runs WinExec to drop and execute the privilege escalation binary. This binary then executes a command (hardcoded ‘cmd’ in our case) as SYSTEM.
The exploit worked pretty reliably in our experiments, but it is interesting to note that a 100% reliable exploit isn’t required - if the exploit crashes the WPAD service, a new instance is going to get spawned when a client makes another request from WPAD service, so an attacker can just try again. There will be no indication in the UI that the WPAD service has crashed, although Window Error Reporting will likely pick up the crash and report it to Microsoft, provided that the user didn’t disable it.
In fact, our exploit doesn’t clean up gracefully and will crash the WPAD service once it runs its payload, so if we keep serving the exploit PAC file after the service has been exploited, it will just get exploited again. You can see the effect of that in Image 7, which was taken after leaving the exploit server running for some minutes and making a lot of HTTP requests in the victim machine.

Image 7: Did we leave the exploit running for too long?
Conclusion
Executing untrusted JavaScript code is dangerous, and executing it in an unsandboxed process is even more so. This is true even if it’s done by a relatively compact JavaScript engine such as jscript.dll. We identified 7 security vulnerabilities in it and successfully demonstrated reliable code execution from local network (and beyond) against a fully patched (at the time of writing) Windows 10 64-bit with Fall Creators Update installed.
Since the bugs are now fixed, does this mean we are done and can go home? Unlikely. Although we spent a fair amount of time, effort and compute power on finding jscript.dll bugs, we make no claims that we found all of them. In fact, where there are 7 bugs, there is likely to be an 8th. So if something doesn’t change it is quite possible we’ll see a chain like this used in the wild someday (and that is, of course, optimistically assuming that attackers don’t have this capability already).
So, what can Microsoft do to make future attacks like this harder:
- Disable WPAD by default. In fact, while the other operating systems support WPAD, Windows is the only one where it is enabled by default.
- Sandbox the JScript interpreter inside the WPAD service. Since the interpreter needs to execute a JavaScript function with well defined inputs and return the output string, sandboxing it should be pretty straightforward. Given the simplicity of the input-output model, it would be great if Microsoft introduced a sandbox of comparable restrictiveness to seccomp-strict: Some processes really do not need more privileges than “receive a bit of data”, “perform a bit of computation”, “return a bit of data”.
In case you want to take action on your own, the only way to prevent this type of attack using new, currently unknown vulnerabilities, seems to be to completely disable the WinHttpAutoProxySvc service. Sometimes this can’t be done in the Services UI (“Startup type” control will be grayed out) due to other services depending on WPAD, but it can be done via the corresponding registry entry. Under “HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WinHttpAutoProxySvc” change the value of “Start” from 3 (manual) to 4 (disabled).
These are some of the advices commonly found online when searching for “disabling WPAD” that did not work to prevent the attack in our experiments:
- Turning off “Automatically detect settings” in Control Panel
- Setting “WpadOverride” registry key
- Putting “255.255.255.255 wpad” in the hosts file (this is going to stop the DNS variant but likely not the DHCP variant)



.PNG)





0 Comments:
Post a Comment