Posted by Stephen Röttger
In this blog post I want to present crbug.com/944062, a vulnerability in Chrome’s JavaScript compiler TurboFan that was discovered independently by Samuel (saelo@) via fuzzing with fuzzilli, and by myself via manual code auditing. The bug was found in beta and was fixed before it made it into the stable release of Chrome, but I think it’s interesting for a few reasons and decided to write about it. The issue was in TurboFan’s handling of the Array.indexOf builtin and at first it looked like an info leak at best, so it was not clear that you can turn this into an arbitrary write primitive. Besides that, it’s an instance of a common bug pattern in JIT compilers: the code was making assumptions at compile time without inserting the corresponding runtime checks for these assumptions.
The Vulnerability
The vulnerable code was in JSCallReducer::ReduceArrayIndexOfIncludes, in one of the optimization passes of TurboFan that would replace Array.prototype.indexOf with an optimized version when it knows the elements kind of the array. If you’re not familiar with elements kinds in V8, I recommend to check out https://v8.dev/blog/elements-kinds. In short, array elements can be stored in different ways, for example as floats or as tagged pointers in fixed size C++ arrays or in a dictionary in the worst case. Thus, if the elements kind is known the compiler can emit optimized code for the specific case when accessing the elements.
Let’s take a look at the vulnerable function:
// For search_variant == kIndexOf: // ES6 Array.prototype.indexOf(searchElement[, fromIndex]) // #sec-array.prototype.indexof // For search_variant == kIncludes: // ES7 Array.prototype.inludes(searchElement[, fromIndex]) // #sec-array.prototype.includes Reduction JSCallReducer::ReduceArrayIndexOfIncludes( SearchVariant search_variant, Node* node) { CallParameters const& p = CallParametersOf(node->op()); if (p.speculation_mode() == SpeculationMode::kDisallowSpeculation) { return NoChange(); } Node* receiver = NodeProperties::GetValueInput(node, 1); Node* effect = NodeProperties::GetEffectInput(node); Node* control = NodeProperties::GetControlInput(node); ZoneHandleSet<Map> receiver_maps; NodeProperties::InferReceiverMapsResult result = NodeProperties::InferReceiverMaps(broker(), receiver, effect, &receiver_maps); if (result == NodeProperties::kNoReceiverMaps) return NoChange(); [...] |
For Array.p.indexOf, the compiler infers the map for the array using the InferReceiverMaps function. The map presents the shape of the object, e.g. which property is stored where or how the elements are stored. As you can see at the end of the function, the code will bail out if the map is not known and not optimize the function any further (result == kNoReceiverMaps).
On the first look, this seems reasonable until you notice that InferReceiverMaps has three possible return values:
enum InferReceiverMapsResult { kNoReceiverMaps, // No receiver maps inferred. kReliableReceiverMaps, // Receiver maps can be trusted. kUnreliableReceiverMaps // Receiver maps might have changed (side-effect). }; |
The returned maps can be unreliable, meaning side effects of previous operations could have changed the map, for example turning float elements into dictionary elements. However, the type is mostly reliable: an object can’t turn into a number.
That means if the maps are unreliable and you want to depend on anything besides the instance type, you will need to guard against changes with a runtime check. There are two ways to add runtime checks for your assumptions. You can for example insert a CheckMaps node in the effect chain here that will bail out if the map is not the expected one.
Or alternatively there’s a feature called compilation dependencies that will not add a check to the code that relies on the assumption but instead to the code that changes the assumption. In this case, if the returned maps are marked as stable, meaning no object having this map ever transitioned out of it to a different map, you could add a StableMapDependency. This will register a callback to deoptimize the current function which gets triggered if an object ever transitions out of that stable map. There’s a potential for bugs here either if the compiler performs such a check without registering the corresponding compilation dependency or if some code path invalidates the assumption without triggering the callbacks (check out this SSD Advisory for an interesting example).
The vulnerability in this case was that the compiler didn’t add any runtime checks at all in the case of unreliable maps and we get an element kind confusion. If you change the elements kind at runtime from float to dictionary, Array.p.indexOf will run out of bounds since a dictionary with an element at index 100000 is much shorter than a packed array of 100000 floating point values. You can see this behavior in Samuel’s proof-of-concept. Here’s a slightly cleaned up version of it:
function f(idx, arr) { // Transition to dictionary mode in the final invocation. arr.__defineSetter__(idx, ()=>{}); // Will then read OOB. return arr.includes(1234); } f('', []); f('', []); %OptimizeFunctionOnNextCall(f); f('1000000', []); |
Information Leak
The first step to exploitation will be to turn this bug into an info leak. Note that Array.p.indexOf is checking for strict equality on the elements, which mostly boils down to a pointer comparison for heap objects or a value comparison for primitives. Since the only return value we get back is the index of an element in the array, our only option seems to be to brute force a pointer.
The idea is to turn a float array into dictionary mode to get indexOf to read out of bounds and brute force the searchElement parameter until it returns the OOB index of the pointer we want to leak, in particular the pointer to the storage of an ArrayBuffer. We also need to put our search value in memory behind the leaked pointer so that all the unsuccessful attempts don’t run out of bounds of the heap and trigger a segfault. Our memory layout will look roughly like this:

Our ArrayBuffer pointer will be page aligned which reduces the brute force a bit. But to speed up the attack further we can use another trick that allows us to brute force the upper 32 bits separately. V8 has an optimization that allows it to store small integers (Smi) and heap objects in the same place by using a tagged representation for the latter. On x64, all pointers will be marked with a one in the least significant bit and Smis have the lowest bit set to zero and the upper 32 bit are used to store the actual value. By checking the least significant bit, V8 can distinguish between a Smi and a pointer and doesn’t have to wrap the former in a heap object.
That means, if we use an array with tagged objects and Smis for our OOB access, we can brute force the upper 32 bit of our pointer by using a Smi as our searchElement parameter.
When implementing this attack, I always triggered crashes in which the bug ran out of bounds of the heap without running into the boundary I put in memory. It seemed difficult to get the right memory layout for my two step brute force to work. However after debugging for a bit, the real problem turned out to be a different one. After around 0x2000000 tries with my float brute force, the garbage collector kicked in and moved my objects around, breaking the required heap layout. Fortunately, this problem is easy to avoid: if the brute force was not successful after 0x1000000, reallocate the ArrayBuffer and start over until the pointer ends up in the right range.
Arbitrary Write
Now how can this bug be turned into an arbitrary write? When I said that the strict equality check mostly boils down to a pointer comparison, I didn’t mention a special case: strings. Strings in V8 have multiple representation. The regular string that consists of a length and the bytes in memory is represented by the SeqString class. But there’s also a SlicedString which is a slice of another string, a ConsString which is a concatenation of two other strings and more.
If V8 compares two strings, even with strict equality, it will first check that the length and the first character are the same and if that is true flatten the two strings to a SeqString to be able to compare them easily.
Since we already know the address of controlled memory with the pointer to our ArrayBuffer, we can create a fake string object in there and use the OOB read bug to trigger a type confusion between a float and a heap object. This allows us to call flatten on our fake string. My first idea was to overflow the buffer that is allocated for the result by crafting ConsStrings in which the left length plus the right length is larger than the total length. This works and I believe it might be possible to exploit it this way, however after the overflow I always ended up in a situation in which the next write would happen at an offset close to INT_MIN or INT_MAX and trigger a segfault.
There’s a more generic way to turn this into an arbitrary write by abusing the marking phase of the garbage collector (recommended reading: https://v8.dev/blog/trash-talk). But to understand it, let’s take a step back and look at the memory layout in V8. The heap is organized in multiple so-called spaces. Most new allocations end up in the new space, which itself is split into two. The memory is allocated linearly here, which makes it very easy to control relative offsets between objects. A round of garbage collection will then move objects from one part of the new space into the other and if they survived two rounds of collection they will get moved into the old space. Besides that, there are some special spaces for different objects, for example for large objects, for maps or for code. At the time of writing, spaces are always aligned to 2<<18 or 2<<19 bytes so you can find space-specific metadata for a given heap object by masking off the lower bits of the pointer.
So what happens if the garbage collector kicks in while V8 is processing our fake string object? It will traverse all the live objects and mark them as such. For that, it’s starting with all globals, all objects currently on the stack and depending on the type of GC run optionally all objects in the old space that have pointers to the new space. Since our fake string object currently lives on the stack, the GC will try to mark it as live. To do so, it will mask off the lower bits of the pointer to find the space metadata, take a pointer to the marking bitmap and set the bit at the offset that corresponds to the offset of our object in the space. However, since the storage of our ArrayBuffer is not a V8 heap object and thus doesn’t live in a space itself, the metadata can live in user-controlled memory too. By setting the bitmap pointer to an arbitrary value, we gain a primitive to set a bit at any chosen address. The final memory layout will look roughly like this:
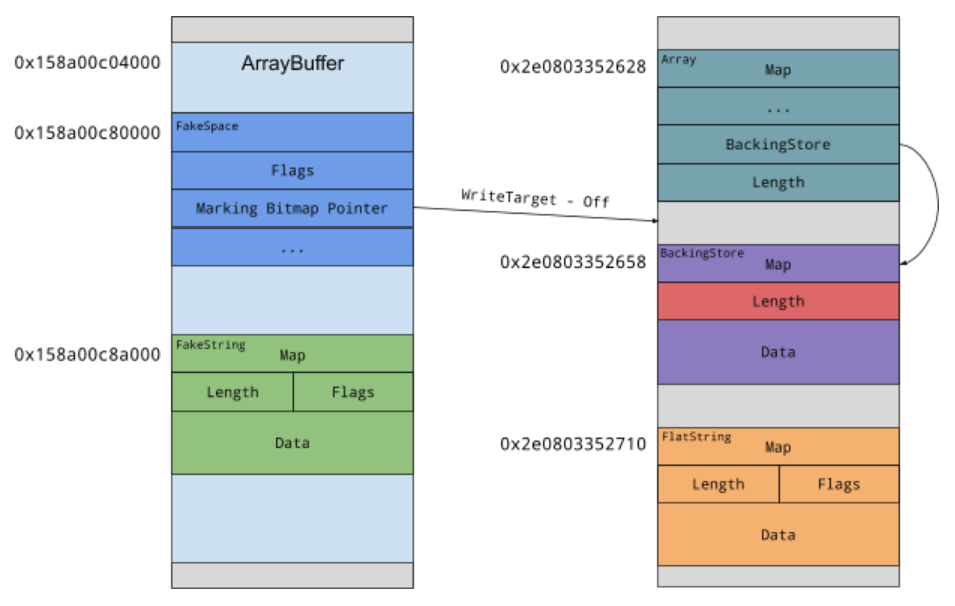
As the target for the overwrite, I chose the length of an array backing store since that gives a very reliable primitive that is easy to turn into an object leak and arbitrary write. The only remaining obstacle is to leak the address of the length field. We could try to brute force that address again but this would take a bit longer since the pointer won’t be page aligned this time.
Instead, we can use the string flattening operation to get a pointer to the new space if we trigger it right. We create a fake ConsString to be flattened using our OOB primitive again. As a reminder, we just need to set the first character and the length correctly to start the flattening. The allocation will then end up either in new or old space depending on if the original string itself was in the new or old space. We control this by setting a flag in our fake space metadata. After the flattening happened, V8 will replace the left pointer of our ConsString with a pointer to the flattened string and the right side with an empty string and we can read these pointers back from our ArrayBuffer. Since allocations are happening linearly in the new space our array to corrupt will be at a predictable offset.
After we corrupted the length field of the array, we can use it to overwrite other data on the heap to gain the primitives we want. There are many write-ups online where to go from here, for example check out this great blog post by Andrea Biondo (@anbiondo). You can find the exploit up to the array length corruption here. It’s written against a manual build of Chrome 74.0.3728.0.
Conclusion
As has been shown many times before, often bugs that don’t seem exploitable at first can be turned into an arbitrary read/write. In this case in particular, triggering the garbage collector while our fake pointer was on the stack gave us a very strong exploitation primitive. The V8 team fixed the bug very quickly as usual. But more importantly, they’re planning to refactor the InferReceiverMaps function to prevent similar bugs in the future. When I noticed this function in the past, I was convinced that one of the callers will get it wrong and audited all the call sites. Back then I couldn’t find a vulnerability but a few months later I stumbled over this newly introduced code that didn’t add the right runtime checks. In hindsight, it would have been worthwhile to point out this dodgy API to the team even without vulnerabilities to show for.
Besides that, a proactive refactoring like this could have been done by an external contributor and would have been a great candidate for the Patch Reward Program. So if you have an idea how to prevent a bug pattern, even for vulnerabilities found by other researchers, think about running it by the V8 team and contributing to the code and it might be eligible for a patch reward.



.PNG)





0 Comments:
Post a Comment